Cache effects, illustrated
22/Nov 2017
Few years ago I published an article about love and care for your cache. Every now and then I receive emails asking for clarification or some extra question. It seems like the basic rules are easy enought, but once you add multiple cores to the mix, it might get a little bit confusing.
If we only have one core everything is fairly simple. There’s just 1 cache, which is essentially a variant of hash-table with limited number of slots. If cache line (=N bytes) is not in the table, it’s loaded from memory and from now on, it’ll stay there until we fill the entire table and need to make more space. Simple and fun.
Things get a tiny bit more complicated when we introduce other cores with their own caches (but still reading/writing from/to the same system memory). It is now possible entries in our cache get invalidated because of something that other core is doing. I will try to illustrate some of these cases using Agner Fog’s performance counter library.
As mentioned, complications start when we have more than 1 core trying to access main memory. To be more specific at least one of them needs to be changing it, after all, if everyone is only reading, no real synchronization is necessary. To ensure all cores play nice with each other, a cache coherence protocol is employed, in our case it’s the MESI protocol. I will not describe it in detail, it’s pretty well documented and in any case I could never do it better than this document (seriously, if you only read 1 paper on memory - make sure it’s this one).
TLDR version of MESI is - each letter represent a state that a cache line can be in:
- Modified: line “owned” by 1 cache only and modified, ie. value differs from the one in main mem,
- Exclusive: line owned by 1 cache, not modified
- Shared: line possibly stored in other caches (same value as main memory, otherwise it’d be M)
- Invalid: not present/unused
In our theoretical example with cores only reading, lines would be only in ESI states.
Reading
Let’s try that first: 2 threads, 2 cores, both threads simply reading 1000 sequential 4-byte numbers, so the inner loop is:
mov eax, DWORD PTR [ecx]
add ecx, 4
cmp ecx, OFFSET ?buffer@@3RCJC+4000
jl SHORT $LL25@TestLoopResults:
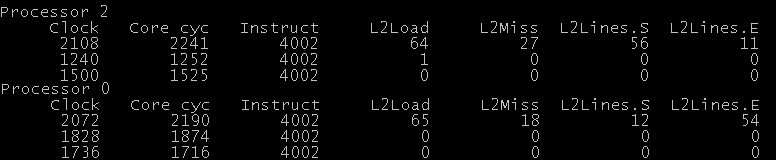
- L2Loads = L2 load operations
- L2Miss = L2 misses
- L2Lines.S = L2 lines in the S (shared) state
- L2Lines.E = L2 lines in the E (exclusive) state
More or less, as expected. We loaded 1000 items, my CPU cache line is 64 bytes, so 16 integers per request = ~63 requests. Reads from different cores overlap, so we get some lines in shared state, but no dependencies, so it all goes fairly fast (4k instructions in 2k cycles).
Writing
Moving to something more interesting - writing (so actually forcing some inter-core communication). Using 10k iterations now (1000 is fast enough one thread is almost completely done in some cases), still 2 cores running 2 threads, thread 0 is reading, thread 1 is writing to the same variable. We’re not concerned with races here, just want to see how does it affect performance/cache state.
Results:
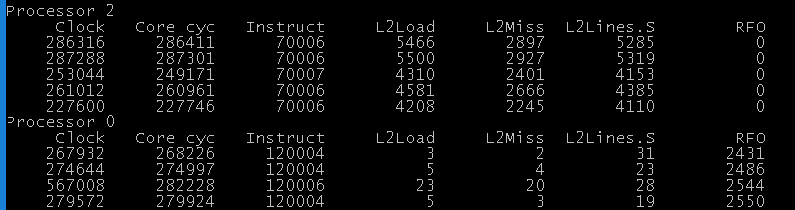
New counter:
- RFO = number of RFO operations (Read For Ownership)
As you can see our performance drops dramatically. For the thread reading the data, the code didn’t change much (if anything, it should be faster, we keep loading the same variable!). The problem here is what other cores are doing – they/it keep invalidating our cache line, causing us to reload it constantly.
Writing, continued
OK, let’s try something else, read/write from/to unrelated variables. Setup is pretty much the same as before, but our read/write functions look like:
// Volatile to make sure compiler doesn't decide to optimize it out
volatile long x = 0;
volatile long y = 0;
// Compiles to: mov eax, DWORD PTR ?y@@3JC ; y
void ReadVar()
{
if (y)
{
}
}
// mov eax, DWORD PTR _v$[ebp]
// mov DWORD PTR ?x@@3JC, eax ; x
void WriteVar(long v)
{
x = v;
}Results? Suprisingly (or not..), almost the same as before (2 cores accessing the same variable). As most of you probably have guessed by now (or could see it coming) – this code is prone to false sharing. As mentioned - our protocol operates on cache lines, not individual bytes/words. If x and y happen to share the same line (and it is very likely as they reside just next to each other) - writing to one of them will cause the RFO that invalidates the whole line.
To confirm, let’s add some fake padding to make sure these 2 variables do not share a cache line (64 bytes in my case):
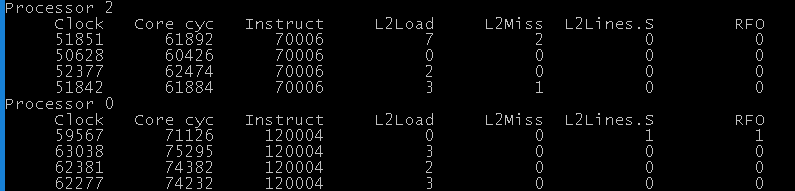
64 dummy bytes, 5x speed-up.
Writing, same core
Finally, one more experiment. Let’s go back to step 2 when we were accessing the same value from 2 threads, generating thousands of RFOs and stepping on each other toes all the time. The only difference is, this time, I’ll set the thread affinities so that they both run on the same core. This means - in theory - that no inter-core communication is necessary, but let’s verify that:
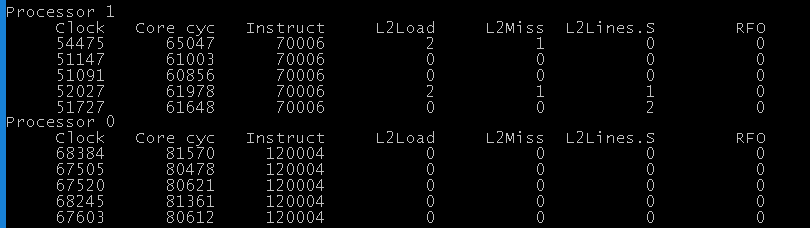
Phew, no surprises there. My laptop is Ivy Bridge, which means each core has own L2 (+ L3 shared between them all). Since x sits in only 1 cache (shared by both threads), we expect this line to be in the Modified state and never invalidated.
Hopefully presented examples will paint a little bit clearer picture of what’s behind a seemingly innocent write opertation.